We have too many bugs
I have heard this statement from product managers several times in my career. I have a boilerplate response to this:
I am sorry, we didn’t get the number of requested bugs as part of the requirements, so we picked a random number. If you wish to define the number of bugs you’d like to see in the next version, please add it to the requirements. You can pick any natural number larger than 0.
When saying this out loud, I usually get a staggering look, a moment of thought, and a laughter, in this order. You see, the statement of “too many bugs” is not well defined at all. As a result it is very hard to work with such an unquantified statement, and even harder to fix.
The cost of bugs can be huge, and it is highly important to identify where the feeling of “too many” stems from.
Dean Peters had done an outstanding work in his post about the cost of bugs, and I will not repeat his work, go have a look there. And as he mentions his math only touches on direct bug costs, not on the indirect costs.
Bug types and impacted environment
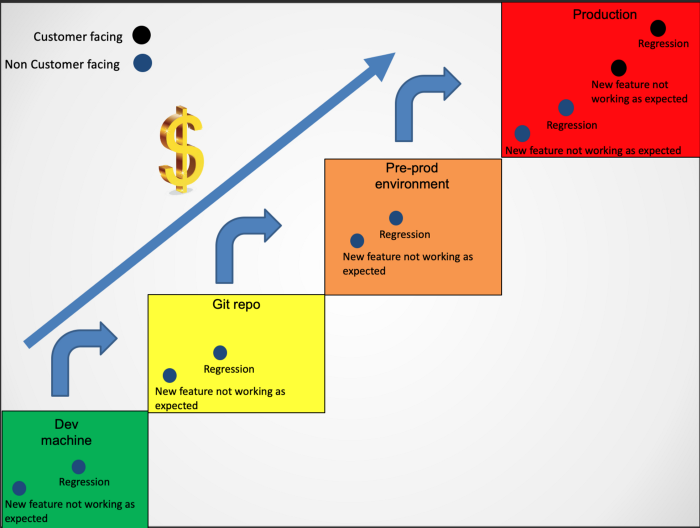
Cost of bugs illustration
I drew a small diagram to explain my thoughts around costs of bugs, and how to identify where your real issues are.
From the diagram above it is easy to notice I differentiate between bug types, and where we have discovered them. This is crucial in my opinion. And I will explain why.
A regression is a much more problematic type of bug, especially when it is customer facing. It means something was working and upon change it broke. This leads to customer dissatisfaction, and to a whole can of quality discussions we really want to avoid. Along with fear of change, lack of trust and other similar things we would like to avoid.
On the other hand, new features coming out with bugs are tolerable in most cases, and in most industries. In order to avoid those, I usually suggest finding an early adapter, a design partner or other venue of a customer getting early, exclusive access allowing them to comment on the feature as early as possible to avoid discovering the bugs after we announce our new capability.
So those are the two main bug types. You probably wonder why I call issues found during development bugs, and why I bothered putting them in my chart. The reason for this is to reflect the other part of the equation: bugs found early, are worth gold. The earlier you find a bug, the better your situation is, especially if the bug type is a regression. Bugs found on the developer machine are the best bugs on earth, and I would be happy to find as many of them as possible.
However, and this is a very important point — finding bugs costs money as well, and you might be change wary due to the fear of finding bugs in front of customers. This in turn leads to investing endless amounts of time and money to find bugs, slowing down the development, or in worst cases, bringing it to a halt. Basically, if I had unlimited time and money, I could potentially find all bugs. After all if you ask me how good I am at finding bugs, i would ask you how much you are willing to invest in it.
How do I fix it?
In order to respond to the “too many bugs” claim, one needs to collect the data showing what bug types are surfaced, where are they discovered, and walk the way down the environments in order to find the bugs earlier, and with fewer regressions as possible.
Each type of bugs requires its own treatment and each environment requires its own treatment.
Regression bugs require a very good set of regression tests, all the way from the developer machine up to the pre-prod environment. If your pre-prod differs from production, that is also something you should fix in order to find the issues outside production. Additional protection method is good test code coverage, that ensures that even bizarre code paths are covered.
On the other hand, new feature type of bugs requires writing new test cases as part of writing the code, and other test driven delivery methods, along with having real users look at your deliverables, as mentioned above.
Once you have ironed out the identification of bug types, you should also work on pushing the discovery to be as early in the cycle as possible. Methods such as commit hooks, automated merge tests, continuous integration and continuous delivery help a lot in those fronts, as well as having the environment setup and artifacts going through the cycle pipeline identical to production.
Conclusion
You need to have metrics. You need to track which bug originated from what version, what was the bug type, where was it discovered, by what tool or (I hope not!) customer, and what measures are needed in order to prevent it from happening again in the future. Prevention deserves a post on postmortems, but that will be for another day